
In control theory, observability is a measure of how well the internal states of a system can be inferred from its external outputs. If a system is perfectly observable, then in theory you can reconstruct the complete internal state just using the outputs.
Software observability aims to do exactly this: every trace, metric, and log is an external output we emit so that we can infer the key states of a system — its performance, safety, and quality. Similarly, the field of mechanistic interpretability is dedicated to observing the latent space of deep neural nets like LLMs.
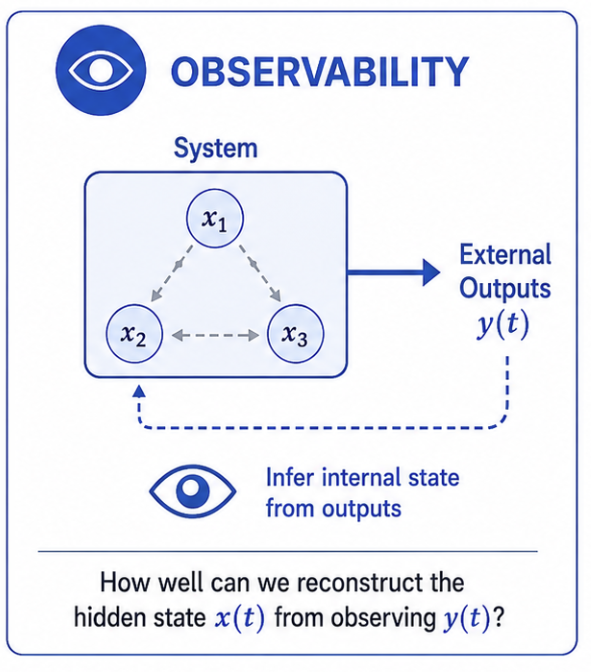
When LLMs arrived, AI Observability became indispensable for understanding how agents behave in production. Agentic systems are complex and unpredictable — they use several tools, read large corpuses, and perform long sequences of actions. Observing agents slowly becomes the gateway to controlling them.
But last week, reading a page-long response from Claude, I realized it had no idea what I actually took away from it. Specifically, it didn’t get any data about:
- the two paragraphs I skimmed
- the one interesting sentence in the middle I dwelled on for 10 minutes
- the half I skipped entirely
- that chart I scrolled up to revisit multiple times
All of that — everything about what I understood — collapsed into the handful of words I typed back. That was the only output it got to observe.
And that's when the symmetry struck me.
Observability runs both directions
Observability doesn't only run from human to machine. The machine is simultaneously making sense of the human too, using the human’s external outputs. And just like AI Observability, if we provide more signal about the human mind — working memory, attention over outputs — perhaps we could improve AI’s understanding of humans.
Now, I’m not asking you to install a Neuralink in your head.
I decided to test if 2 things specifically enabled the LLM to provide better responses:
- Working Memory: Which concepts and facts are easily accessible in the reader’s brain?
- Attention: Which chunks of information did the reader focus on in the previous output?
Together they're a rough proxy for the thing the model never sees: what the reader actually understood. For both of these I did some research and prototyped instrumentations.
Instrumenting Attention
The best measurement for attention is eyeball movements, which is hard to do without a camera that’s constantly on. But there’s a simpler proxy. Eye-tracking studies going back twenty years find that the mouse pointer roughly tracks gaze, especially during natural reading.
Pause here — is your mouse currently pointed at this sentence? Interesting, isn’t it!
The same research says something else worth knowing before you trust any of this. Reading isn't uniform. Attention clusters toward the top-left of a page and decays out toward the bottom — the well-known F-pattern — and on a screen, most of the time is spent above the fold, decaying sharply the further down you go. Position shapes attention as much as content does.
So I tracked what I could actually get from a browser: where the cursor sits, what's on screen, how long it lingers, how fast you scroll.
Four signals, one score per section, recomputed every 300ms:
- Viewport overlap — how much of the section is on screen
- Mouse proximity — how close the cursor is, falling off over ~10 lines
- Dwell — how long the cursor has lingered there
- Scroll calmness — slow scroll means reading, fast scroll means fleeing
Weighted sum, bounded in [0, 1]. Mouse gets the most weight (0.35), scroll the least (0.15) — proximity is a sharper signal than velocity.
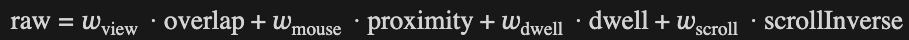
Two details did most of the work.
- Dwell charges fast and leaks slow. Linger in a section and it fills up over ~30 seconds; leave and it drains at a tenth of that rate. Attention you earned by actually reading shouldn't evaporate the instant your cursor moves. It mirrors memory — quick to form, slow to fade.
- Attention rises faster than it falls. The score is smoothed, but asymmetrically: it snaps up when you engage and decays gently when you look away. A glance away isn't abandonment. Off-screen and cursor-gone, a section decays toward zero. Tab loses focus, it's zeroed outright — you're not reading if you're not here.
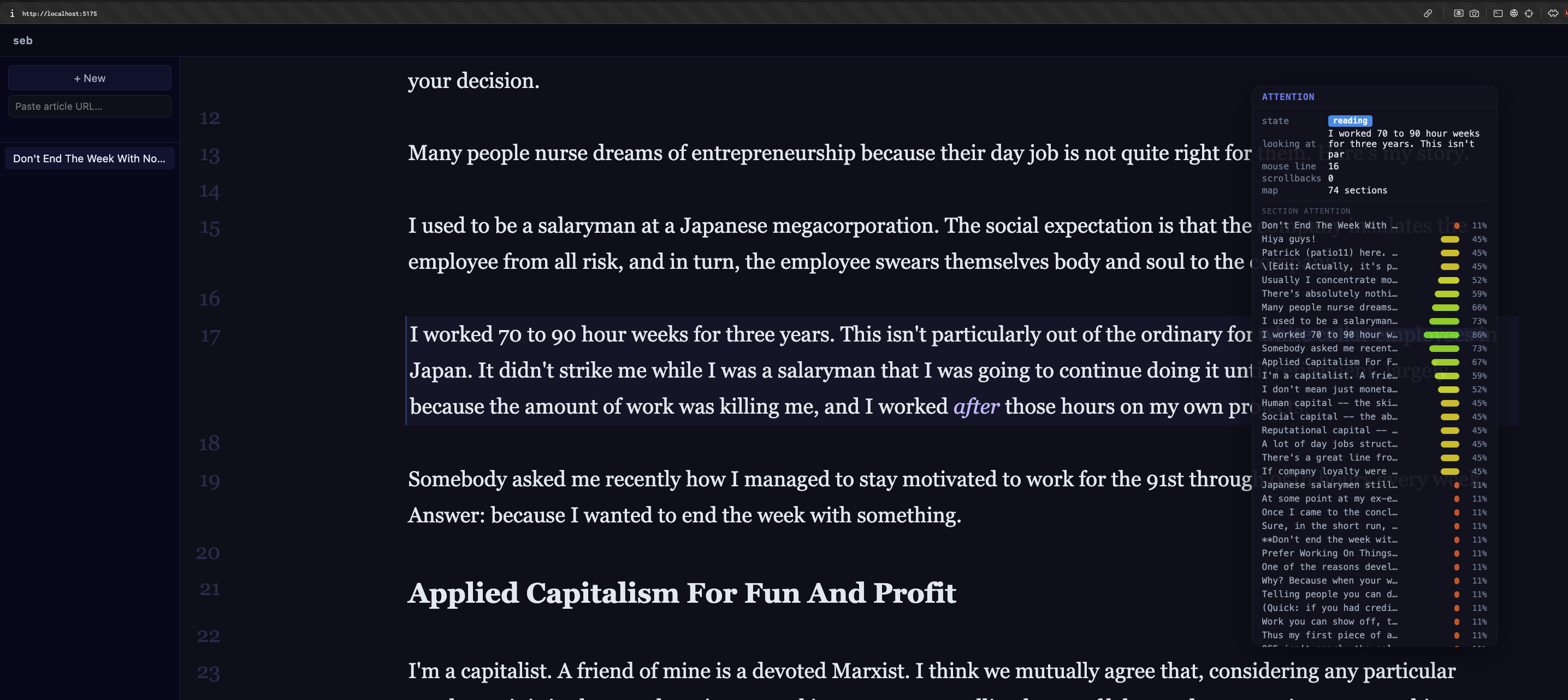
The output isn't just a number. Sorted by attention, the top section drives a state: reading, skimming, re-reading, examining, idle, away. The machine now has a guess at what you're doing — not just what you typed.
Instrumenting Working Memory
Attention over one response is the easy half. The harder question is the first bullet: what's accessible in my head right now?
While it’s hard to read or measure thoughts without invasive surgery, I took the more practical approach of monitoring every single keystroke on my computer — every Google search, every Claude input, every Slack message. This ended up being a great proxy for working memory, and Macs readily provide this information.
I based my Working Memory pipeline around some neuroscience fundamentals:
- Human brains can hold a maximum 3-4 concepts at once. Cowan puts real working memory closer to four chunks, three under load. Whatever I model, it can't be a long list. It has to be the handful of things actually live.
- Working memory is ephemeral. Working memory is a ~20-minute window, not a record of your day. So I only look back 20 minutes. Anything older is a different memory system — out of scope.
- Not everything makes it into working memory. You perceive continuously; you maintain selectively — only attended, task-relevant material gets rehearsed in the store (Baddeley’s central executive). So the pipeline doesn’t mirror feeds. It synthesizes down to what was actually in hand: foreground app, typed intent, loops you’re still holding.
This is almost an exact mirror of a mirror of LLM Evaluators in AI observability:
- agent traces → use LLM Evaluator to compute a metric (eg. retrieval quality)
- human traces → use LLM Evaluator to compute a metric (eg. working memory)
Here’s the high level architecture of my agent. I ended up feeding much more than keyboard inputs. A supervisor thread used these feeds and ran a working memory agent every tick and stored it.
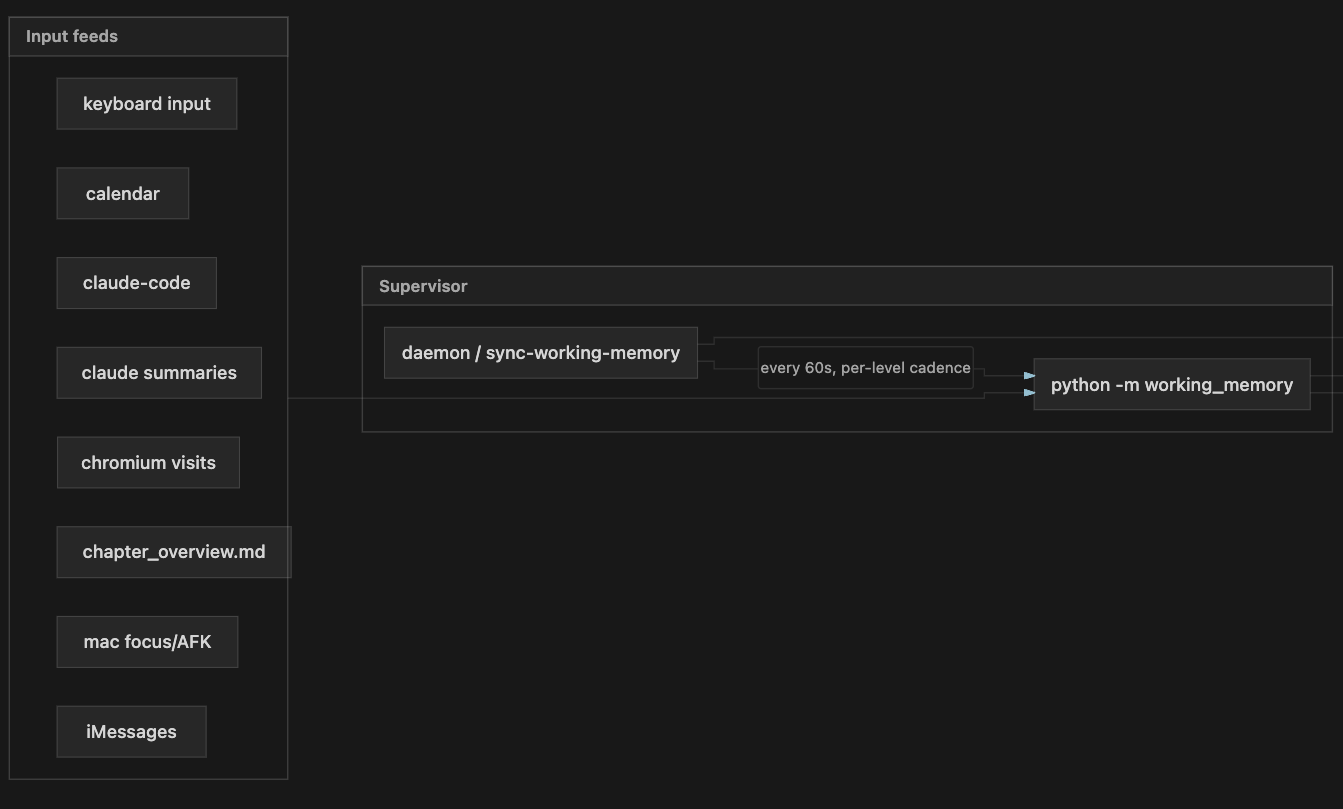
The result was uncomfortably accurate and detailed. Here’s my working memory right now as I’m writing this sentence.
So… does it work?
Honestly: I don't know yet. This began as a weekend curiosity, and I soon started running into walls. Here are my conclusions:
Attention data is incomplete
It is definitely possible to measure attention over a long piece of text using viewport data and cursor movements. However, what happens in the reader’s brain when attending to a snippet remains a mystery, and might be the more important missing piece.
Working memory is noisy
Working memory can be approximated based on your computer activity — they’re effectively a semantic layer over your computer logs. But most of this information is useless and noisy. When you input text to the LLM, your brain is forced to compress your intent into the message, which is pure signal.
Knowing how to use the information is difficult
Measuring attention and working memory only give you scores — but a score by itself tells you nothing about what to do. That's the part nobody mentions about observability, human or otherwise. The dashboard is the easy 20%. Knowing what to do when the line moves is the whole job.
The final bottleneck
We spent years making machines observable to us. Traces, metrics, evals, interpretability — an entire stack for inferring a system's hidden state from its outputs. The other direction barely exists. The human stays a black box, emitting signal the whole time, and we throw nearly all of it away.
That's the bottleneck. As the bandwidth between humans and machines widens, we will be able to expand beyond text — to video, brain activity, possibly even heart rate and hormones.
What’s unclear is the marginal improvement to quality this will bring. Written language is great precisely because it makes you refine and compress your thoughts, edit them, and signal intent directly. The richest signal might be the one you choose to send, not the one leaking out while you read.
But that's a bet about degree, not direction. Even if the typed message stays the highest-bandwidth channel, it's still a brute approximation for everything that happened in your head. The human is the last unobserved system in the loop — emitting signal the whole time, almost all of it discarded. Whether we read it from a cursor, a camera, or something we haven't built yet, that's the next thing worth instrumenting.