How to Escape the Eval Cold Start Problem
You shipped a working demo. Your evals passed. Then you went to production — and everything changed.
Users asked questions you never anticipated. Your agent took paths your test suite never imagined. The carefully maintained eval set you spent weeks building? Mostly irrelevant. You weren't sure what to fix, because you weren't sure what "correct" even meant anymore.
We’ve seen this movie before: the moment your agent meets real users, your mental model of it breaks.
So why is building agents getting harder as tooling gets better?
In this article, we'll explore what is changing about the way we build agents, the new challenges this creates for evals, and how to adjust your methodology accordingly.
Agents Are Becoming More General
Early agents were structurally rigid and semantically narrow. A 2022 LangChain agent retrieved over a fixed document corpus, called a defined set of APIs, and completed tasks in 3–10 steps. You could enumerate most of what it would do. That made evaluation tractable: write some representative inputs, check the outputs, ship.
The harness era changed this. Agents now have access to general-purpose primitives — bash, a browser, an IDE — and take on entire domains of work rather than discrete tasks. A single session might span 100s of steps, branch into unexpected subproblems, and touch parts of the environment you never anticipated. Before, the agent chose between 5 tools. Now it uses a bash tool call to invoke one of 1000s of variations of bash commands — the semantic range has exploded.
The trajectory space is no longer enumerable. It's effectively unbounded.
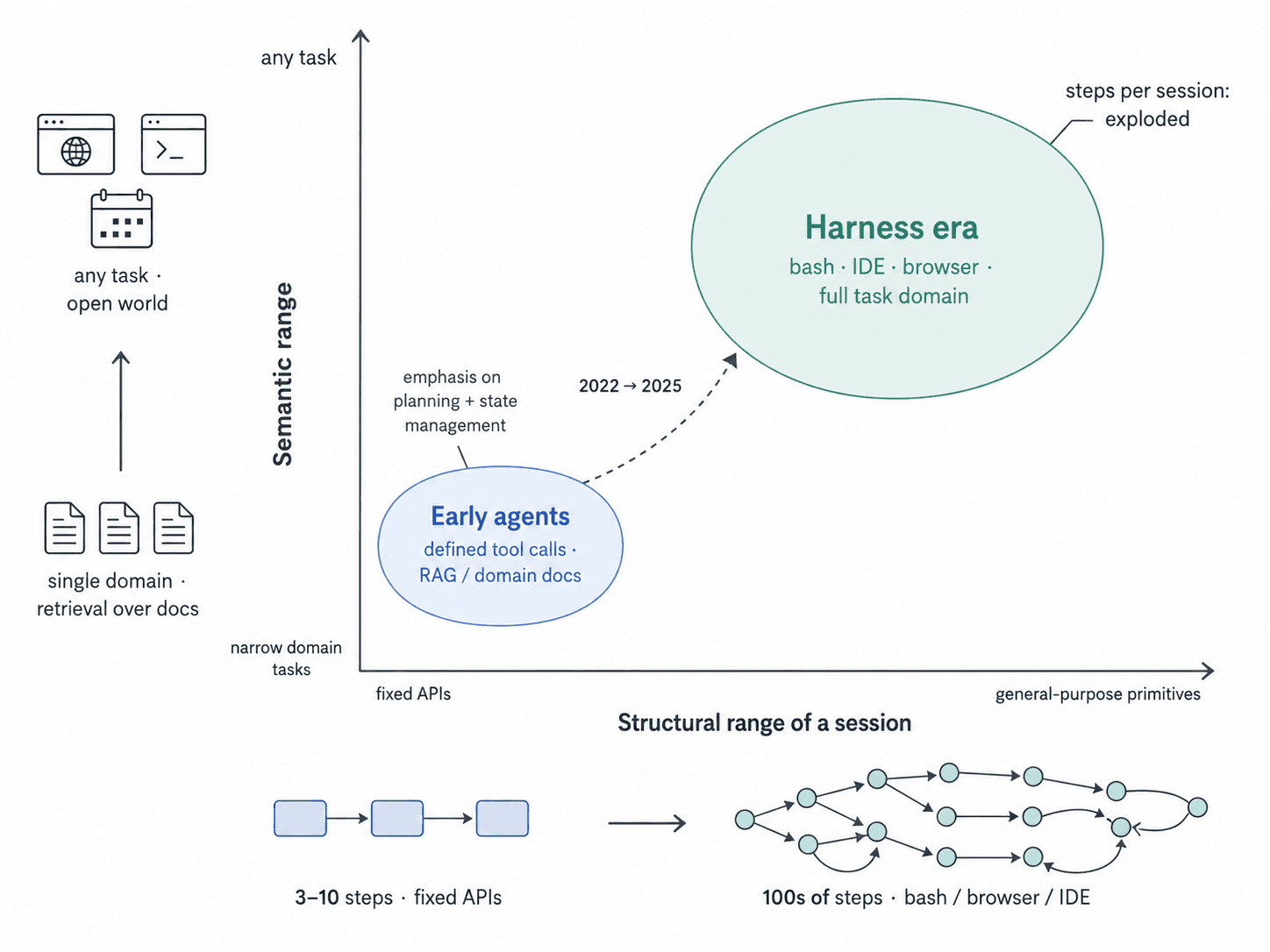
This shift has a direct consequence for evals: when agent behavior becomes unbounded, so does the space of possible failures. You can't write tests for what you can't anticipate. And the more general your agent becomes, the wider the gap between your test environment and production reality.
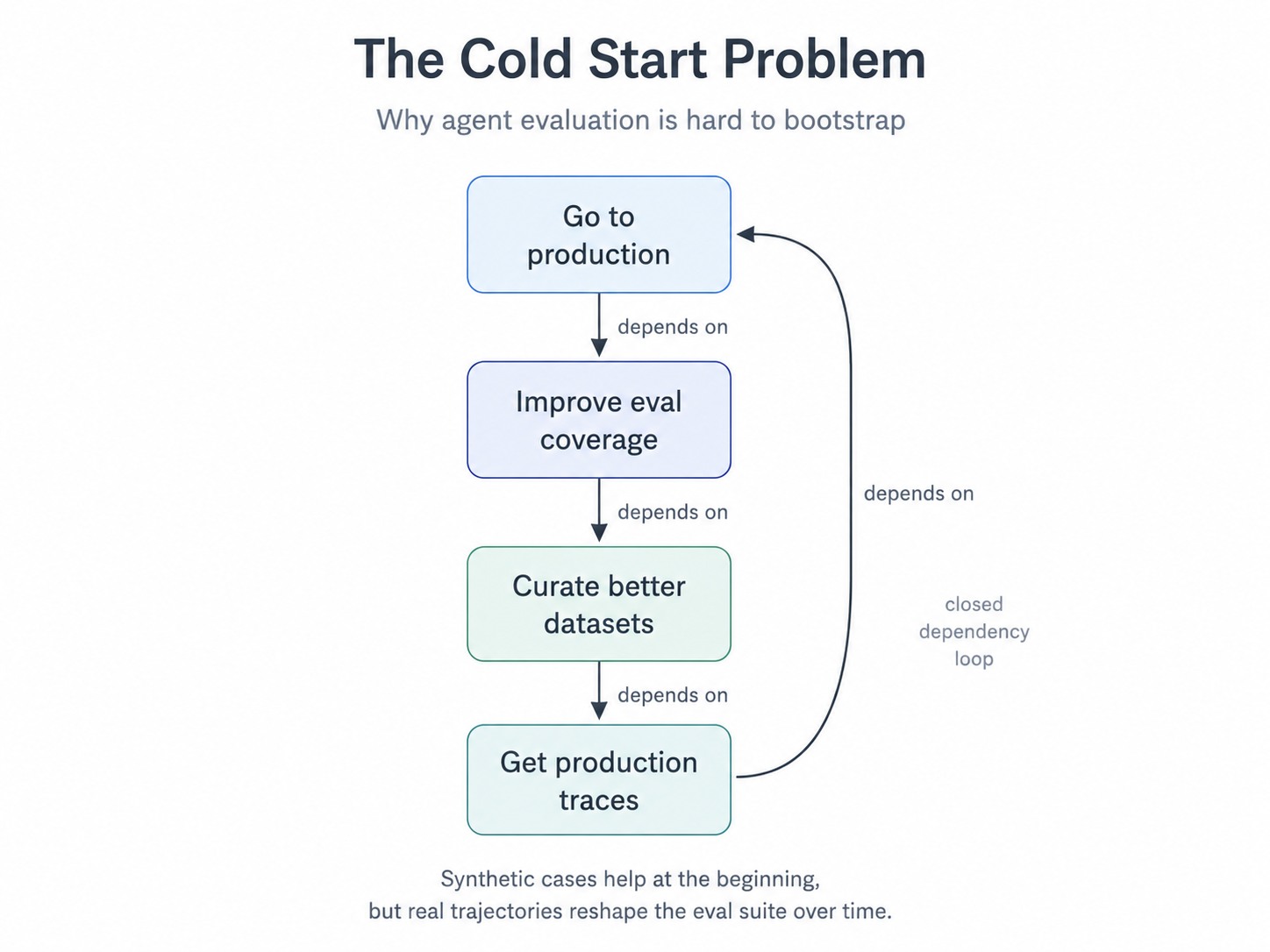
The Cold Start Problem
Before the harness era, getting meaningful eval signal was tractable. The general recommendation was to start with 20–50 hand-reviewed examples — enough to cover core behaviors for a narrow agent.
That number keeps climbing as agents become more general, because coverage now has to chase an unbounded trajectory space.
This creates a catch-22 at the heart of agent development:
- To go to prod, you need good eval coverage
- For good eval coverage, you need curated datasets
- For better datasets, you need production traces
- To get production traces, you need to go to prod
The obvious escape hatch is synthetic data or hand-crafted cases. But here's the truth: real trajectories are irreplaceable. Hamel Husain and Shreya Shankar — who've trained evaluation practices at OpenAI, Anthropic, and Google — are explicit that synthetic data generates the inputs you already thought of. Real users bring the ones you didn't. Anthropic's engineering team makes the same point from their work on Claude Code: the eval suite started narrow and hand-crafted, and only became genuinely useful once it was fed by real production behavior and failure modes.
This isn't an argument against synthetic data. It's an argument about sequencing. Synthetic cases are a cold-start tool, not a substitute for production signal. The eval suite you build before launch will look significantly different from the one you have six months later — and that's a feature, not a failure.
The Production-to-Dataset Flywheel
The ideal state for any agent team is a self-reinforcing loop: observe production behavior → identify failure modes → curate labeled examples → build evals → improve the agent → generate new traces. Each iteration makes your eval suite more grounded and your agent more reliable.
The flywheel compounds — the more real trajectory data you accumulate, the better your evals, and the better your evals, the more confidently you can ship changes.
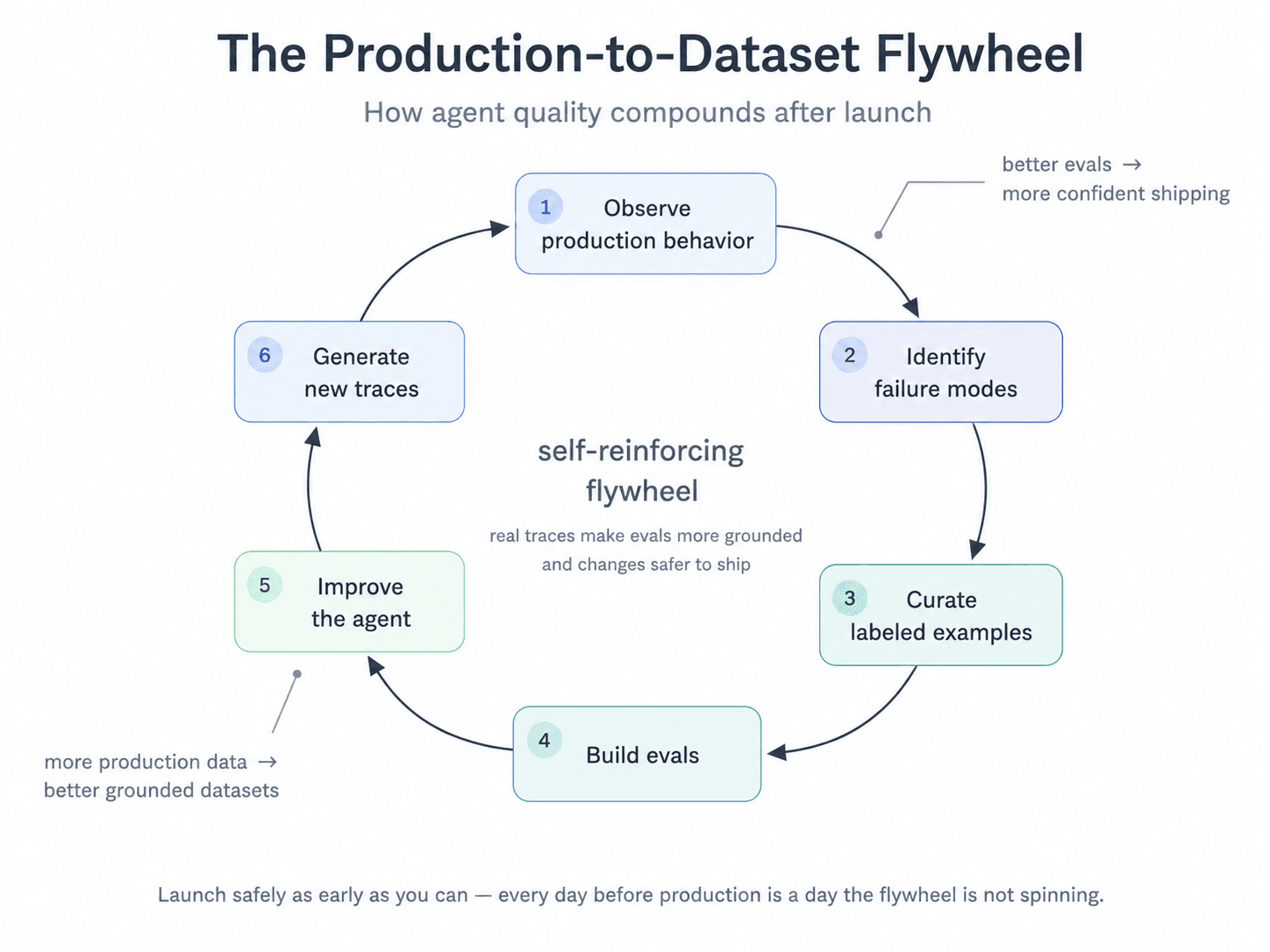
This is the flywheel every team is trying to build. Here’s the bottom line: The Cold Start problem isn't just an inconvenience — it's a direct blocker on the flywheel ever beginning to spin.
No production traces means no labeled examples. No labeled examples means no grounded evals. No grounded evals means you're iterating blind. The flywheel requires production data to start, but getting to production feels like it requires the flywheel to already be running.
But here's what this makes clear: the goal isn't to delay going to production until your evals are good enough. It's to get to production as fast as you safely can. Every day before launch is a day the flywheel isn't spinning.
The question then becomes: how do you get there safely, without a mature eval suite to lean on?
Observability Driven Development
The answer to the cold start problem isn't better synthetic data or more hand-crafted test cases. It's a different contract for what "production-ready" means.
Most teams treat production-readiness as an eval threshold: ship when your offline suite passes. ODD inverts this. Instead of asking "are my evals good enough to ship?", it asks "do I have enough visibility to learn safely once I do?"
The minimum viable agent isn't the one with the best evals — it's the one with the right observability to survive first contact with real users and start the flywheel spinning.
That observability is built on three pillars: Safety, Health, and Outcome. Two of them measure what happens during a session. One of them defines the space within which measurement is even meaningful.
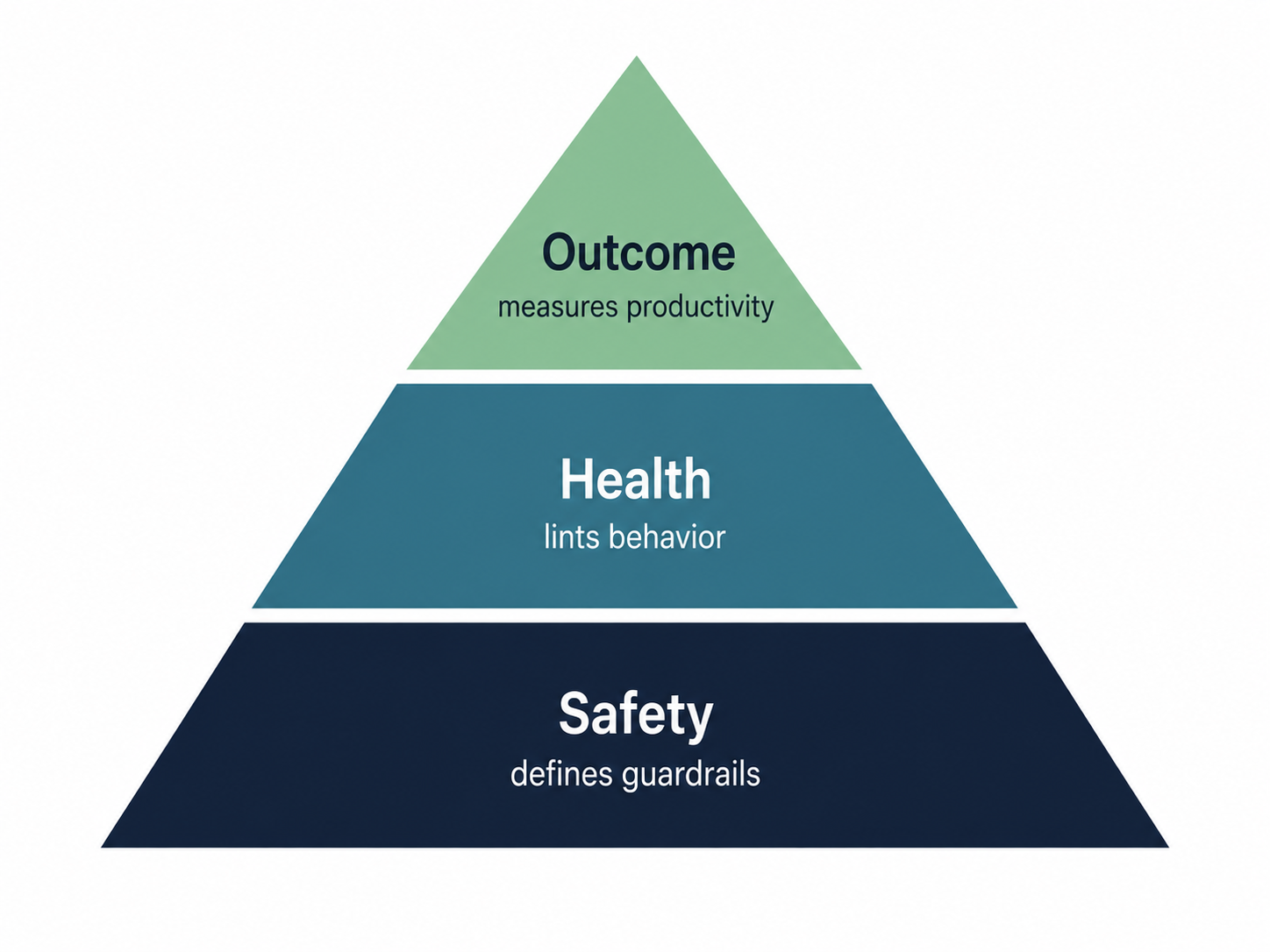
1. Safety — did the agent stay in bounds?
Safety defines what the agent is allowed to do — the boundary of the arena within which measurement is even meaningful. It's the foundation everything else rests on.
These are the landmines you plant deliberately: spend caps, destructive action blocks, policy violations, access controls. Safety runs in two modes: preventive guardrails run inline and block the action before it happens; detective guardrails run server-side and fire an alert after the fact. Which you use depends on your latency budget and how reversible the action is.
Safety is the one pillar where you deliberately tolerate false positives. A missed catastrophe costs far more than a noisy alert, so you tune for sensitivity and loosen later with data.
2. Health — is the agent operating cleanly?
Health is application-agnostic. Think of it as the lint layer for runtime behavior.
It catches the behavioral smells of a poorly engineered agent: looping, repeated tool failures, context bloat, token-budget overruns, malformed tool inputs. This is the move that type systems and linters made for code — eliminating whole error classes before they cascade — applied to agent behavior at runtime. An unhealthy trajectory is a leading indicator: it tends to precede outcome failures, so fixing it lifts performance across every task at once.
Health metrics also read your AI Engineering quality as much as the model's. Healthy traces usually mean the tools, prompts, and scaffolding around the model are sound. And crucially: health runs server-side, computed automatically as traces are ingested. Always on.
3. Outcome — is the agent productive?
Outcome is application-specific. It's your SLO layer — and your most important signal.
It's computed once, at the end of a session, against the state of the world — did the correct refund row actually land in the database — not against the agent's own claim that it succeeded. This distinction matters: agents hallucinate success. Grade reality, not the transcript.
Outcome is path-independent. It doesn't care how the agent got from start to end — only what changed between the two states of the world. A clean, in-bounds trajectory that produced a confidently wrong answer still fails. A messy trajectory that somehow reached the right destination still passes. Outcome catches what Health can't.
It's only as trustworthy as your ability to verify: coding and stateful tasks have checkable ground truth; open-ended synthesis doesn't, and you fall back on a subject-matter expert or a calibrated LLM judge. This is your top line — real impact, ROI, and a direct read on whether the agent is actually useful.
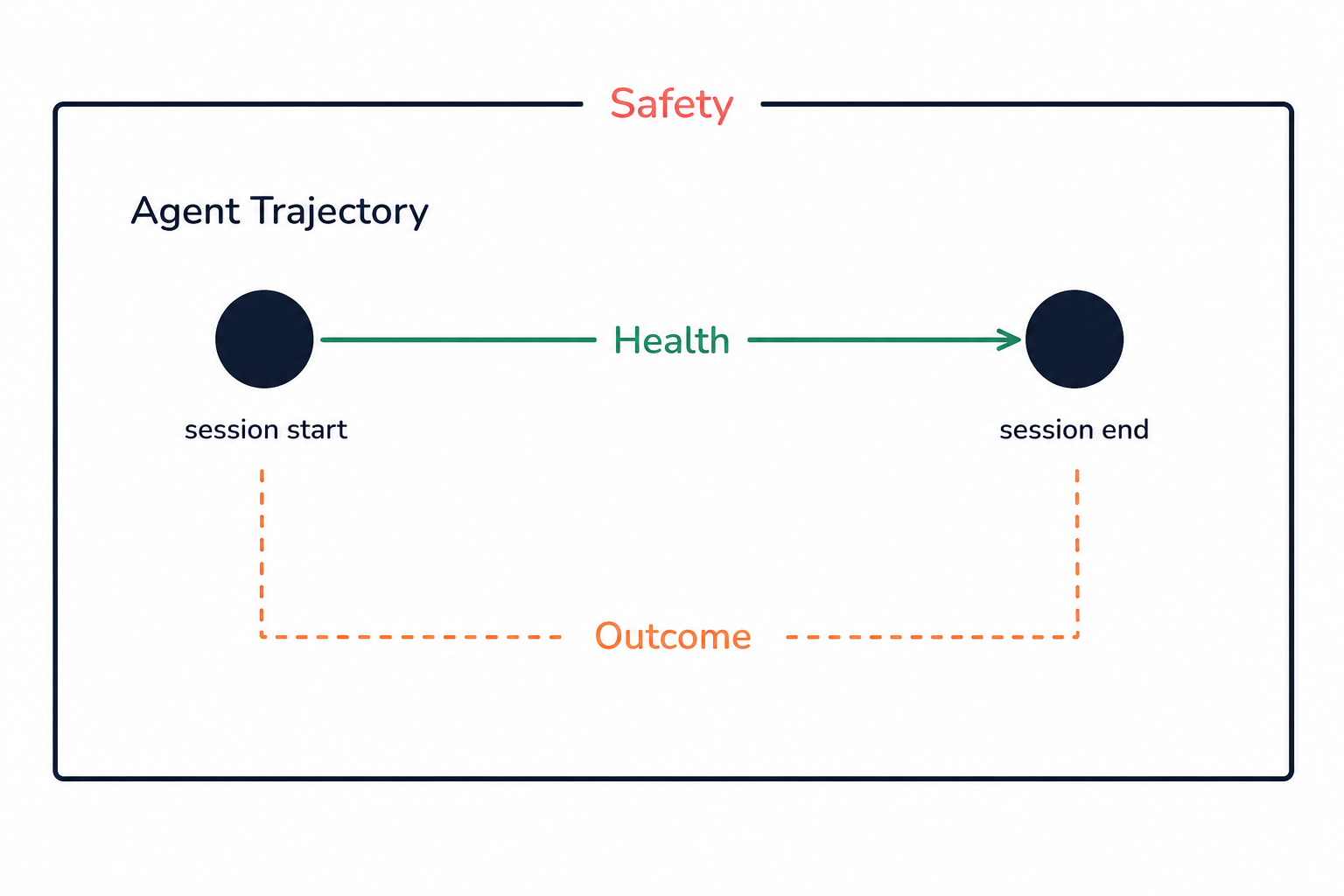
Safety defines the arena. Health and Outcome tell you what's happening inside it. Together they give you enough visibility to ship without a mature eval suite — and enough signal to start building one the moment you do.
Here's how that maps to the full arc of agent development.
The Agent Development Lifecycle
Most agent teams experience the same arc, whether they recognise it or not. Expectations inflate early, reality hits in production, and the teams that come out the other side are the ones who treated the crash as signal rather than failure.
The curve has five stages. But the most important insight isn't what happens at each one — it's how long you spend getting between them.
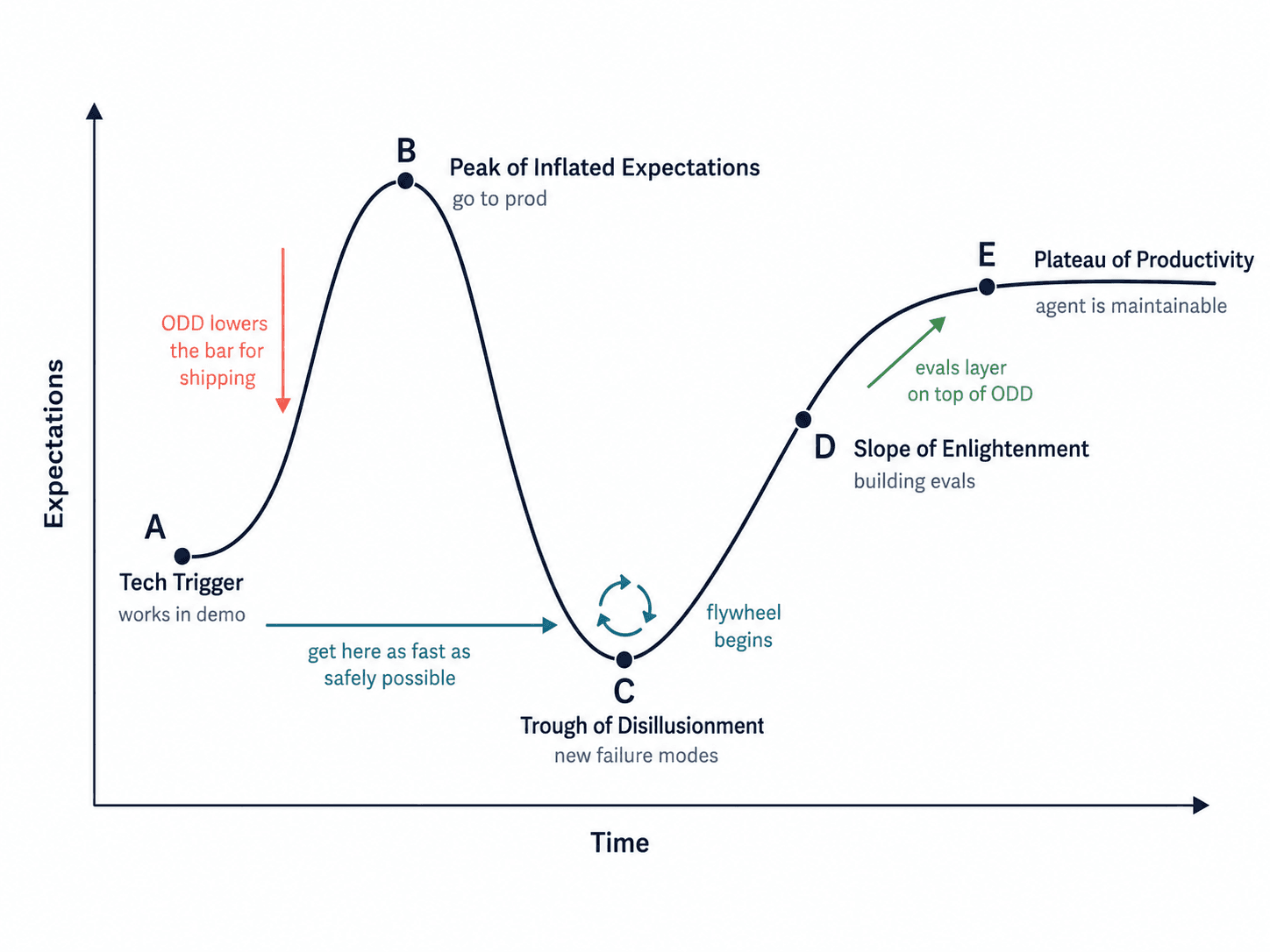
A → B — The Initial Eval Slope.
Before you can ship, there's a climb. Hand-crafted test cases, synthetic data, domain expert reviews — the cold start work that every team has to do before they can justify going to production. This is where most teams underestimate the effort and overestimate the coverage. The eval set feels comprehensive until real users arrive.
ODD shortens this slope by changing what "ready to ship" requires. Instead of needing a mature eval suite, you need health, outcome, and safety instrumentation. That's a lower and more achievable bar — which means less time on the slope, and faster arrival at C where the flywheel begins.
B — Shipping and First Contact
This is the moment to feel good about. Your guardrails are in place, your top-line metrics are running, and you have enough visibility to learn. You don't need perfect evals — you need enough instrumentation to catch what matters and enough curiosity to pay attention.
Resist the pressure to over-engineer before you have signal. The teams that struggle here are the ones treating launch like a final exam — cramming more test cases, tightening more prompts, delaying more weeks. The teams that thrive treat it like the first day of data collection. Ship, watch closely, and let your traces start telling you what your synthetic data couldn't.
When failure modes start emerging — and they will — approach them with curiosity rather than alarm. A new failure mode isn't a bug report. It's a labeled example you couldn't have invented. Your health metrics will flag unhealthy trajectories. Your outcome metrics will catch confident wrong answers. Your safety guardrails will hold the boundaries. You're not flying blind — you're flying with instruments, learning the terrain.
C → D — The Flywheel Begins
This is the most important movement on the curve. At C, for the first time, you know what you don't know. Real failure modes are observable, reproducible, and — critically — curatable. This is when the production-to-dataset flywheel starts spinning in earnest.
The process becomes: observe production traces → identify failure patterns → label and curate examples → build targeted evals → fix the failure mode → generate new traces. Each iteration makes your eval suite more grounded and your agent more reliable. The ODD pillars that got you to production now serve a second purpose — health anomalies become dataset filters, outcome signals identify which sessions to review first, safety alerts flag the highest-priority traces for annotation.
The eval suite that felt impossible to build before launch now grows organically. You're not writing test cases from imagination anymore — you're codifying what production already taught you.
D → E — The Plateau
The flywheel becomes self-sustaining. Prompt changes, model upgrades, new tool integrations — changes that once required weeks of manual testing can be validated against a regression suite that reflects real user behavior. The agent is maintainable. The team moves fast without breaking things.
The distance between A and E is determined almost entirely by how quickly you moved through C. The teams that reach the plateau fastest are rarely the ones with the most sophisticated evals before launch. They're the ones who shipped early with the right instrumentation, let the trough teach them what to measure, and built from there.
Conclusion
As agents become more general, the space of possible behaviors outgrows anything you can reason your way to from a desk. The eval suite you build before launch will not reflect what your agent actually does in production. It can't — because the failure modes that matter are the ones your imagination missed.
The uncomfortable truth is that the only path to a genuinely reliable agent runs through the trough. Not around it, not over it — through it. Production is where you find out what you're actually building. The trough is where the flywheel starts. Every day you spend trying to eval your way to production readiness is a day the flywheel isn't spinning.
This doesn't mean shipping recklessly. It means redefining what responsible looks like. Health instrumentation to catch behavioral smells before they cascade. Outcome metrics grounded in reality, not the agent's own account of its success. Safety guardrails that hold the boundaries while you learn what the boundaries should be. These aren't a consolation prize for not having evals — they're a more durable foundation than most eval suites ever become.
Build the minimum viable agent. Instrument it properly. Ship it. Approach the trough with curiosity, not alarm — it's the most information-rich environment your agent will ever be in. Then let production teach you what to measure, and build your evals from there.
The flywheel is waiting. Go start it.